We will see how to use polars’ out of the box optimizations to
make parallelized kernel density estimations. To this end, I created the polars_kde package, which is a polars plugin backed by some Rust code.
Note
At the time of writing the polars_kde package has version 0.1.4 and is available on pypi.
Info
By now, the standard reference for writing polars plugins is Marco Gorelli’s excellent tutorial here. If you want to learn how the internals of polars plugins work, please have a look at his tutorial.
Tip
Some advertisement: If you haven’t already checked out my other polars plugin polars_sim, make sure to have a look.
The plugin enables very fast approximate joins on string columns (fuzzy matching but with a twist). The implementation is entirely written from scratch in Rust and uses n-gram vectorization of strings with a fast cosine similarity computation using sparse matrices.
Introduction
Kernel Density Estimation (KDE) is a non-parametric way to estimate the probability density function of a random variable. I recently created a basic marimo notebook on how to visualize feature distributions and drift over time, possibly grouped by another categorical variable, e.g. the target of a classifier. See my repository marimo_notebooks for more details or check out the interactive notebook here.
While working on this notebook, I realized that the computations usually involve multiple kde’s for different slices of the data. In order to have a polars built-in method to compute kde’s, I created the polars_kde package. This enables optimized computations and polars-native code (as opposed to for example using scipy).
The updated notebook with the new polars plugin in place can be found here.
If you (trust me) and want to run the notebook in your local environment, simply fire
1
uv tool run marimo edit https://github.com/schemaitat/marimo_notebooks/blob/main/notebook/feature_drift_fast.py
Note
The interactive marimo notebook uses the scipy implementation. The polars_kde package is not yet available as wasm build.
Interactive Marimo Notebook
Adding interactive marimo notebooks to a static blog.
Adding interactive marimo notebooks to a static blog is as easy as adding an iframe for wasm html files. See the docs. The marimo notebooks are self-contained and can be hosted on any static file server.
I integrated this into my workflow by adding a marimo folder containing all the notebooks. Then, each notebook is exported to a same named folder in the public folder (where the rendered blog html lives).
In my Jenkins pipeline, I install the notebooks as follows:
#!/bin/bash
if[ -z "$1"];thenecho"Usage: $0 <output_dir>"echo" output_dir: directory to store the rendered notebooks"exit1fioutput_dir=${1:-public}/marimo
# create a temp directory to store the rendered notebooksmytmpdir=$(mktemp -d 2>/dev/null || mktemp -d -t 'mytmpdir')if[ -d $output_dir];thenecho"Output directory already exists. Clearing it." rm -rf $output_direlse mkdir -p $output_dirfifor notebook in "marimo/*.py";do# remove .py endingdir_name=$(basename $notebook)dir_name="${dir_name%.*}"echo -ne 'Y'| uv run marimo export html-wasm --sandbox --mode run $notebook -o $mytmpdir/$dir_name mv $mytmpdir/$dir_name${output_dir}/$dir_namedonetrap"rm -rf $mytmpdir" EXIT SIGINT SIGTERM SIGQUIT SIGKILL
Rust side
On the rust side of things, all we need to do is wrapping an already existing functionality into a polars expression. Often, this is the standard approach on how to create polars plugins. Another example is for example the polars-reverse-geocode plugin.
You see that I use Normal as kernel and Silverman as bandwidth estimator. This is a common default choice, but a future improvement would be to make these parameters configurable.
Examples
To get the basic idea, we start with a simple example. We have a dataframe with two columns, id and values. We group by id and compute the kde for the values column. We work with a fixed set of evaluation points, which are the points at which the kde is evaluated.
importnumpyasnpimportpolarsasplimportpolars_kdeaspkimportseabornassnsdf=pl.DataFrame({"id":np.random.randint(0,10,10_000),"values":np.random.normal(0,1,10_000),}).with_columns(values=pl.col("values")+pl.col("id")*0.1).cast({"values":pl.Float32})eval_points=[x/100forxinrange(-400,400)]df_kde=(df.group_by("id").agg(kde=pk.kde("values",eval_points=eval_points),).with_columns(# add the evaluation points as a column# for plottingeval_points=pl.lit(eval_points)).explode("kde","eval_points"))sns.lineplot(df_kde,x="eval_points",y="kde",hue="id",)
See also the Readme of the polars_kde for some more examples on varying evaluation points.
Note
The kde function works also on group_by_dynamic groups and is particularly useful for timeseries
aggregations.
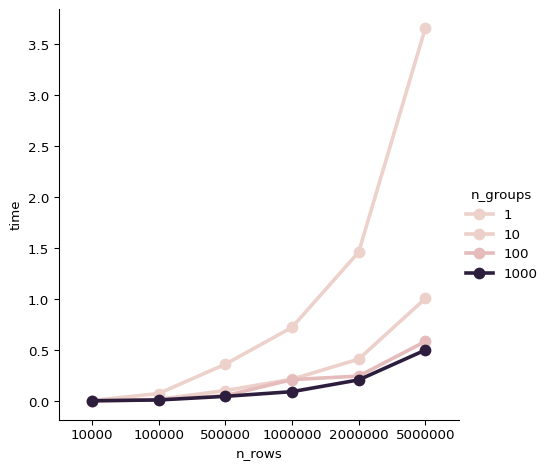
Speed
Especially, for large dataframes and many groups, the speedup is significant. Compared to the scipy implementation, the polars_kde is faster even for a single operation faster. For illustration, let us look at some boilerplate code that can be used to generate more benchmarks.
importnumpyasnpimportpolarsasplimportpolars_kdeaspkimportseabornassnsimporttimedefbenchmark(n_groups,n_rows):df=pl.DataFrame({"id":np.random.randint(0,n_groups,n_rows),"values":np.random.normal(0,1,n_rows),}).with_columns(values=pl.col("values")+pl.col("id")*0.1).cast({"values":pl.Float32})eval_points=[x/100forxinrange(-50,50)]start=time.time()df_kde=(df.group_by("id").agg(kde=pk.kde("values",eval_points=eval_points),))end=time.time()df_bench=pl.DataFrame({"n_groups":[n_groups],"n_rows":[n_rows],"time":[end-start]})returndf_benchbench_n_groups=[1,10,100,1000]bench_n_rows=[10_000,100_000,500_000,1_000_000,2_000_000,5_000_000]# Include this to generate the plot.# Here, I added the output on my local machine with 8 cores,# since the build agent is single core and we would not see# any parallelization.# df_bench = pl.concat([# benchmark(n_groups, n_rows)# for n_groups in bench_n_groups# for n_rows in bench_n_rows# ])# sns.catplot(# df_bench,# x="n_rows",# y="time",# hue="n_groups",# kind="point"# )