Kubernetes basics
introduction
In this post, we will set up a Kubernetes cluster with Linode and deploy a dummpy webpage.
If you want to learn more about Kubernetes, I can recommend the kubernetes 101 tutorial by  Jeff Geerling.
Jeff Geerling.
kubectl
The steps below are executed on macOS in zsh. For other operating systems have a look at https://kubernetes.io/docs/tasks/tools/.
First, check if kubectl is already installed.
|
|
If that is the case you are ready to go. However, check for updates. Otherwise, let us download the latest binary.
|
|
You can also move the binary to any other place as long as the absolute path of the base directory appears in the environment variable $PATH. As always, to persist changes like export PATH=$PATH:/path/to/kubectl, make sure to add that to your .zshrc.
You can verify the installation by typing kubectl version.
To ease your life, we use an alias for kubectl and enable autocompletion. Add this to your .zshrc:
|
|
The change takes effect after your .zshrc has been sourced.
the cluster
As already mentioned, I prefer Linode as cloud provider. If you don’t already have a Linode account, go to Linode and register. Once you are logged in, choose “Kubernetes” on the left panel and click “Create Cluster”.
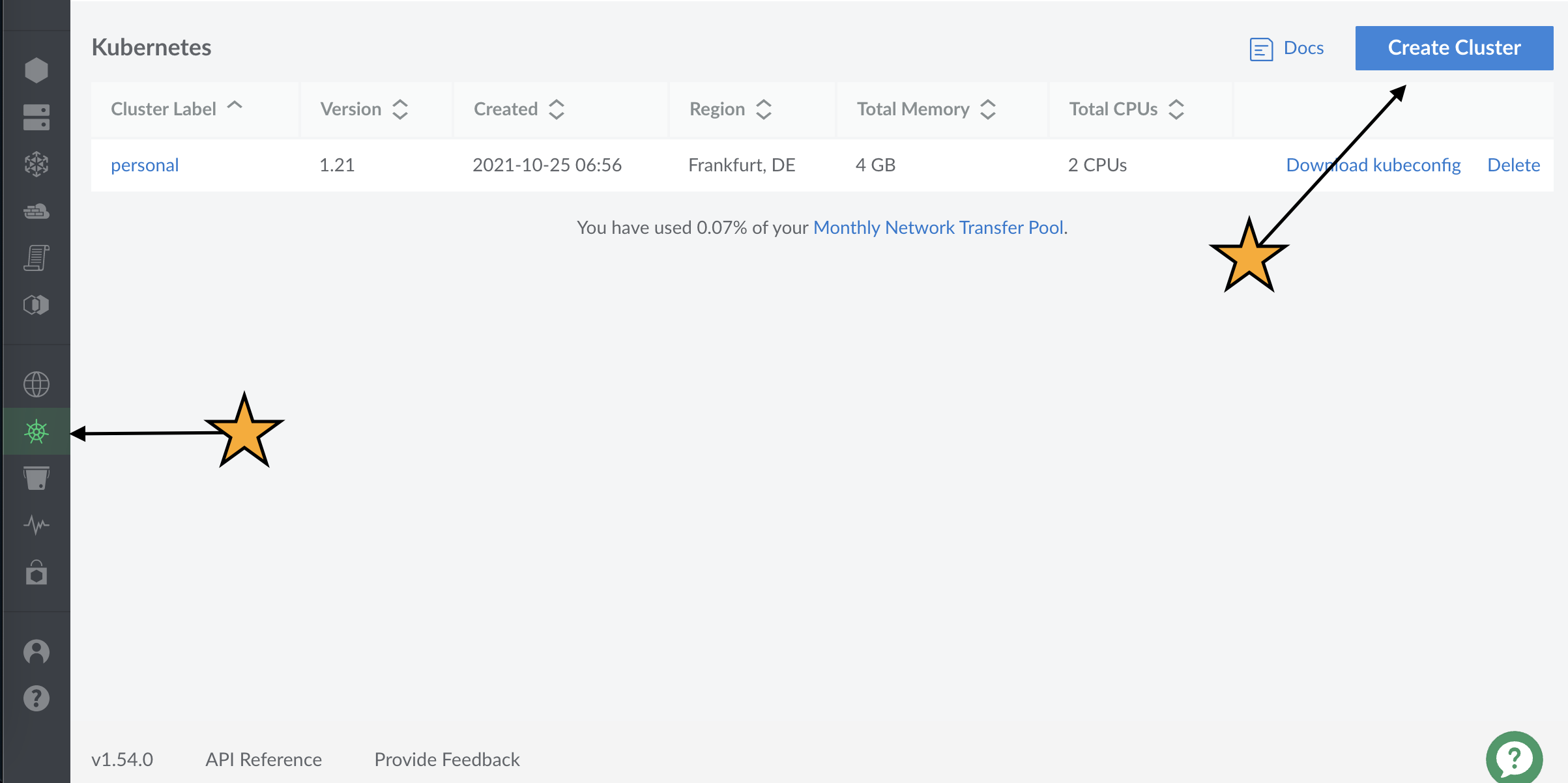
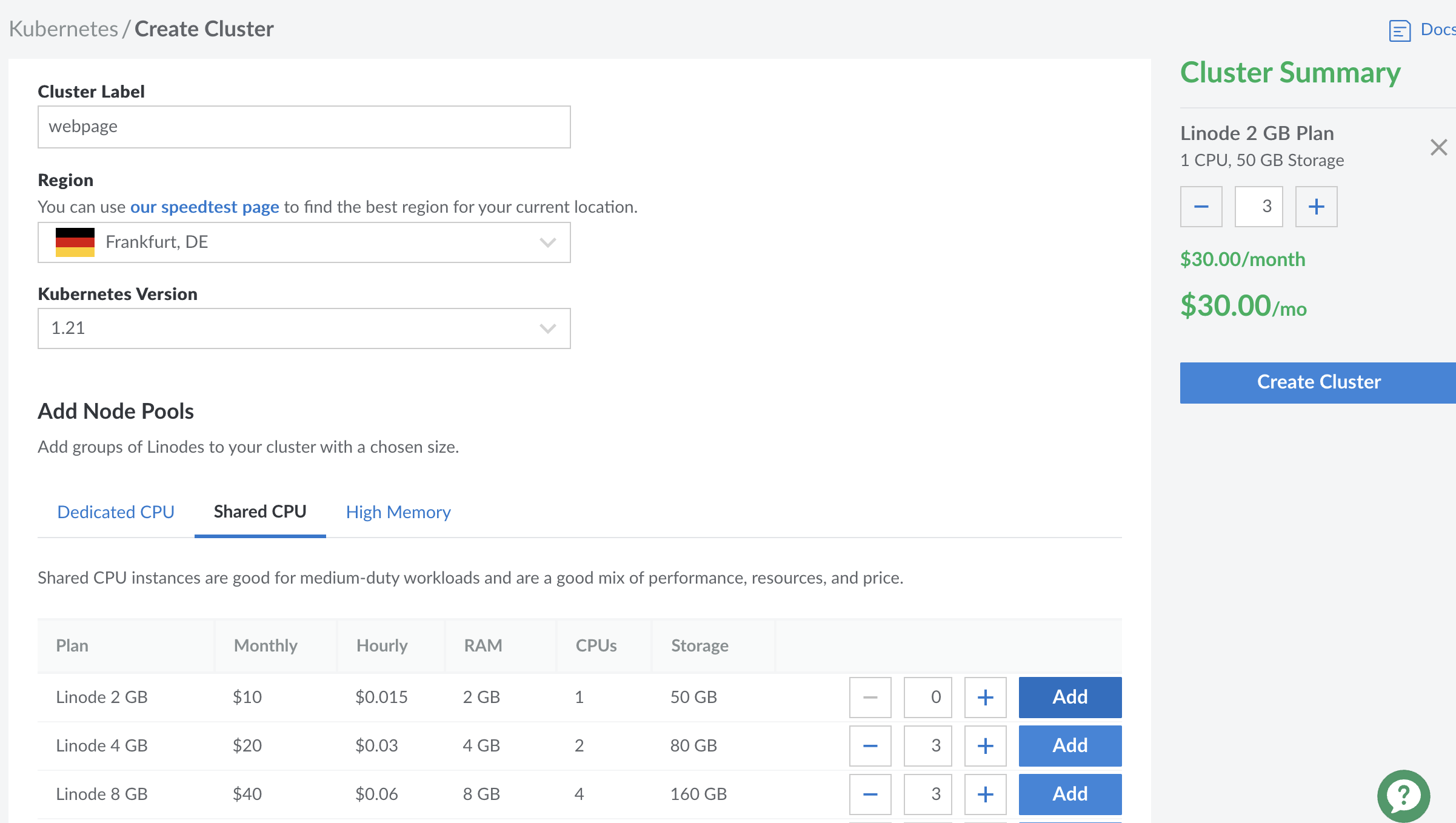
Next, you choose a label for your cluster, a region where the nodes will live and which type of nodes you want to use. For the region, it makes sense to pick a geographically close one. This reduces the latency.
For the tutorial, I chose two Linodes with Shared CPU and 2 GB memory. However, to have enough redundancy, and to make Kubernetes what it is supposed to do, you should have three or more nodes.
While the nodes are starting up, you can already download the cluster specific kubeconfig.yaml.
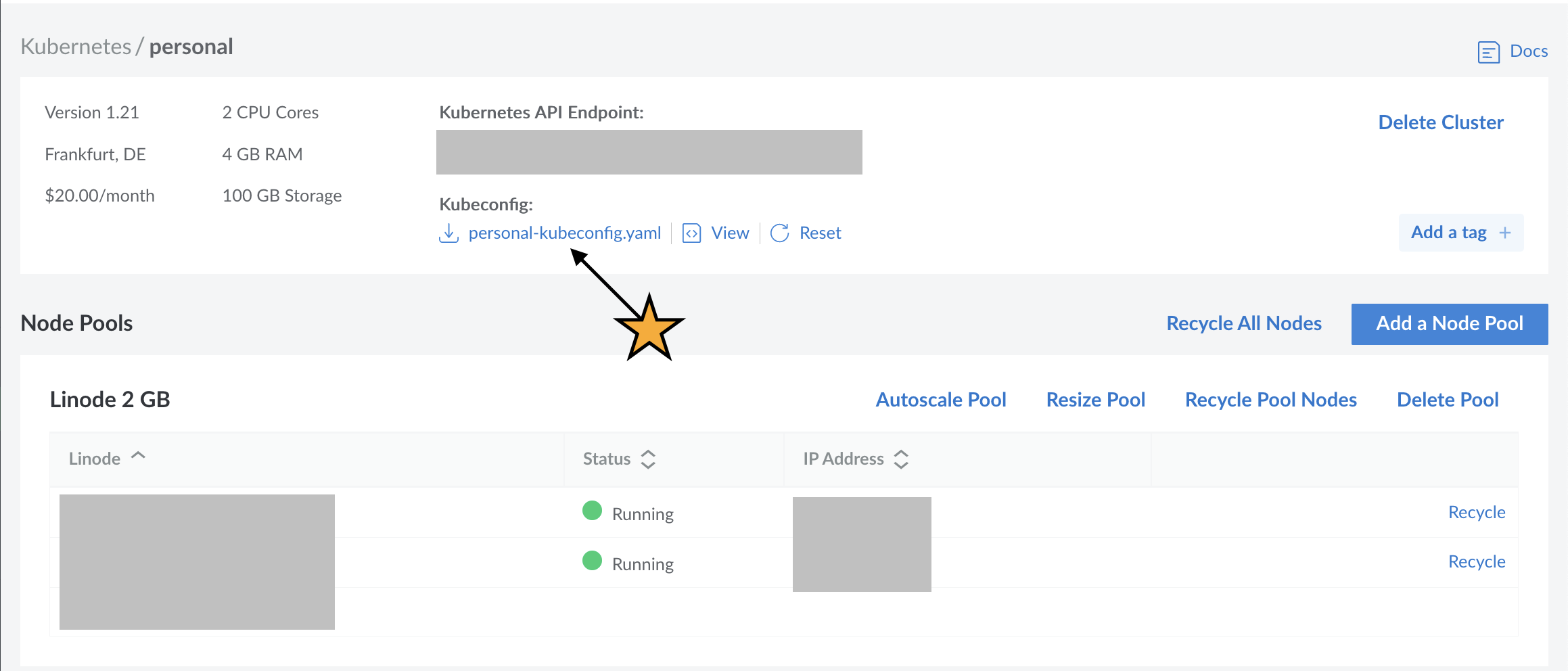
To make the kubeconfig available to kubectl, the $KUBECONFIG variable is used.
The default location is ~/kubeconfig.yaml. Make sure to add the variable to your .zshrc:
|
|
Also, make sure to set permissions. Anyone with the kubeconfig file has full access to the cluster. This is done with
|
|
That gives the owner read permissions to the kubeconfig.yaml.
If everything went as expected, you can verify the setup by typing k get nodes. The output should show all nodes in your cluster.
a toy web app
Our first deployment will be a toy web application running on an Nginx webserver. Later, we will refine this deployment to host our productive website.
With docker we would simply do a
1docker run --rm -d -p 8080:80 nginx:latestThat would start a single Nginx container with its port 80 being forwarded to port 8080. You can check that the service is running with a
curl localhost:8080.
In Kubernetes, we have to define a deployment. The deployment.yaml looks as follows:
|
|
Before applying the yaml, we create a namespace web, which bundles all deployments regarding our web application. Then, we can apply the deployment and watch for pods to start.
|
|
Now, we have a single pod with an Nginx server running in it. To make the web app accessible, we first have to deploy a service:
|
|
targetPort must match the port the Nginx server is listening on. The spec.selector is responsible for assigning pods to the service, as defined in spec.selector.matchLabels in the deployment.By using kubectl we can forward the service port to our local network:
|
|
You should now be able to see a welcome page at localhost:8001.
Another way to expose the service is to change spec.type to NodePort. That opens a static port on the node IP address. The port range is 30000-32767. Let us deploy the following service:
|
|
Next, we have to find the external IP of one of the nodes. You can inspect k get nodes -o wide or get one IP directly by using the json output format together with jq:
|
|
You can then check if the service works by curling $IP:31100.
I hope you got a first impression of how kubernetes works and how to apply deployments.